

Specs, Not Sprints
The playbook we use to ship products fast with AI.


Abnormal AI stops the cyberattacks that legacy tools miss. If your company still treats AI like a pilot program, you’re in the wrong place. AI-powered engineering is our default, and we’re hiring.
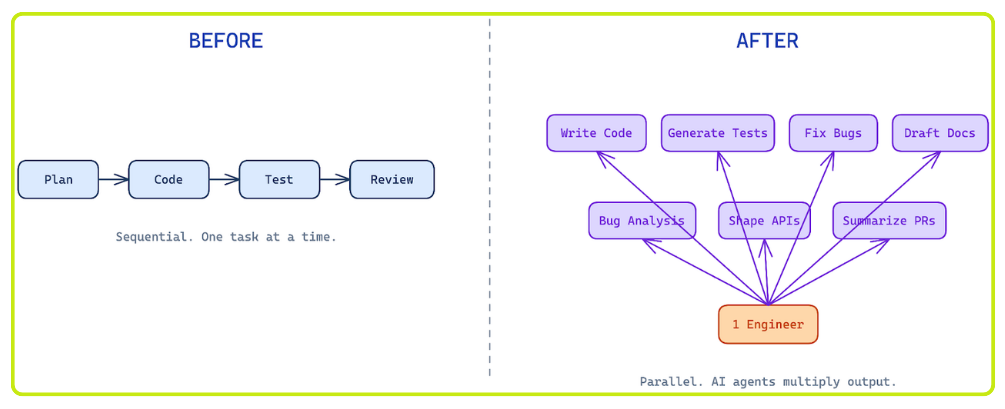
For most of my software engineering career, I operated in a two-week sprint model. We planned projects carefully, broke work into tickets, and optimized for making the best use of everyone’s limited time, since raw engineering hours were scarce and valuable.
Over the past several months at Abnormal, we started seeing coding agents compress work that used to require structured sprint planning and weeks of execution into much smaller time windows. When a single generalist engineer can ship an end-to-end feature in days, two-week sprint cycles create more planning overhead than the execution required.
We decided to try a new working model built around this reality, so we piloted one on a new team building AI tool and agent governance products for SOC teams. Until very recently, this team consisted of just two full-time engineers and two part-time architects.
Here’s how the model works, and what we’ve learned along the way.
Spec-driven development with AI
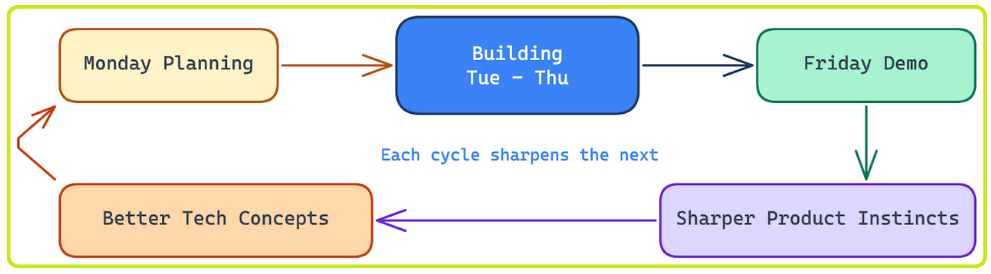
A typical week revolves around a Monday planning meeting and a Friday demo. Everything in between is building.
The Monday Planning Meeting
Before Monday, engineers write what we call a tech concept, a short document covering the intended customer experience, hard product requirements, pointers to relevant code, and key design decisions like database schemas and API contracts. A tech concept always maps to an end-to-end outcome, whether that’s a feature a customer will use or a piece of technical infrastructure that enables one.
Engineers then put this tech concept into our internal planning agent that works directly off our codebase and documentation to generate a first-pass implementation spec. The goal is to walk into our Monday meetings with a concrete starting point for discussion.

When we review these specs, we primarily focus on the most critical decisions that would be expensive to reverse, like the UX in the Abnormal Portal web application, database schemas, and upstream and downstream dependencies. We also track all of our meeting notes and specs in a single Google Doc. We’ve found that keeping everything in one place, rather than spread across multiple tracking tools, makes it easier to stay focused.
The role of AI in this planning workflow is important to frame correctly.
It handles the first draft, scaffolding, boilerplate, and initial structure so engineers can focus on critical decisions like the architecture and product judgment calls.
It solves the cold start problem, since turning a loose mental model into a concrete plan takes time. Having a first draft to react to and critique gets the team thinking and iterating faster than starting from nothing.
The Week of Building
Following our Monday meeting, we spend the majority of our time executing against these specs. Our workflow leans heavily on Claude Code and our in-house coding agent built on top of the Claude Agent SDK; most engineers on the team run roughly five background agents executing against a well-defined plan alongside roughly five local Claude Code sessions for work that may need more back-and-forth.
Running this many agents at once only works if engineers can trust the output. So a key part of how we work is building tools and mechanisms that let agents test their own work. In practice, that looks like agents spinning up a service and hitting endpoints with various request bodies, clicking through a UI via Playwright to verify frontend changes, or using CLIs for external systems to validate behavior.
For example, while I was building a cron for populating security news and incidents, I was able to kick off Claude Code to deploy it our test environment, trigger the cron using a CLI, check the logs for errors using our custom-built CloudWatch CLI, and update a PR description with those testing results.
More recently, while I was building an integration with a third-party agent platform, I had Claude Code trigger sample agents, discover via web searches and CLI which endpoints the platform exposed for fetching execution events, define which ones our integration system needed to pull from, and run a smoke test confirming that our integration systems could connect to the platform end to end.
That level of end-to-end autonomy is what you get when agents have the right tools and the right guardrails.
The Friday Demo Meeting
In our Friday meetings, each engineer demos their work from the week. For key product decisions, we loop in our internal security team. Putting work in front of practitioners within days of it being built means we catch misalignment much faster. Over time, this meeting has helped sharpen every engineer’s product judgment, as not everyone at Abnormal comes from a security background, and most haven’t been in the shoes of a CISO or a SOC team at an enterprise. The feedback from these demos directly informs the tech concepts engineers write up before Monday, which means each week’s plan is shaped by what we learned the week before.
Lessons from this working model
AI output quality is a direct function of context quality.
Like many engineers across the industry are finding, the single biggest determinant of whether an agent produces useful work is how much relevant context it has.
There was one instance early on when insufficient upfront API design led us to model a DynamoDB table around the wrong access pattern. DynamoDB doesn’t let you change primary keys in place, so we had to create a new table with the correct key schema and migrate the data. Since then, we’ve been much more rigorous about key design decisions during our Monday planning, especially ones that are difficult to reverse.
This is especially true for UI changes. We’ve found that agents perform best when they know what the user should see and what should happen at each step of a flow, like what page a user lands on after clicking a button, or what they see when there’s no data. Once we started writing tech concepts that described the intended experience in those terms, the gap between what agents produced and what we actually wanted narrowed significantly. For the final polish, this is often where engineers pair with Claude Code locally to get the UI exactly right.
Traditional job titles are starting to blur.
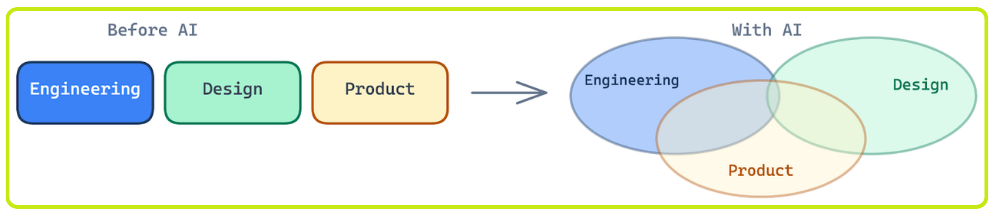
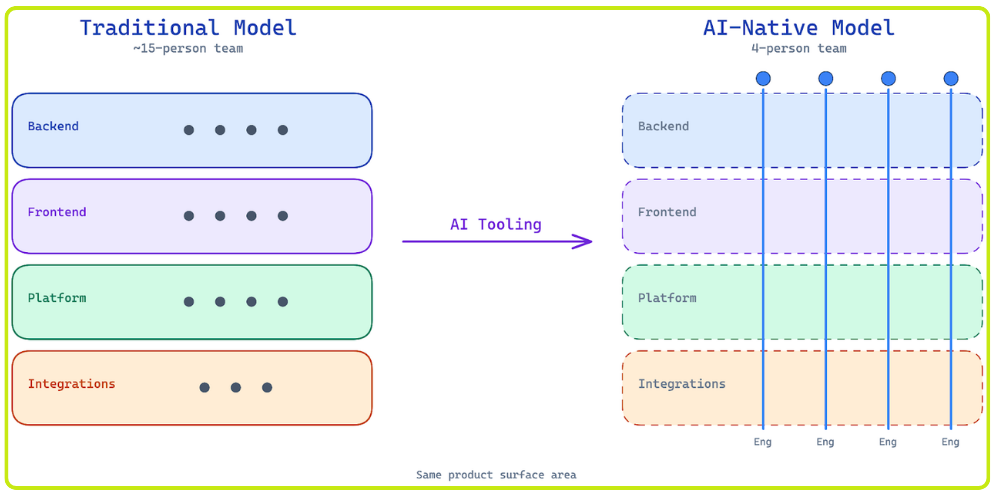
AI tooling has made it practical for people to ramp quickly in areas outside their core expertise, and the result is that a single person can own far more scope than they could two years ago. On our team, we’re seeing that engineers with deep distributed systems and security backgrounds are working on frontend projects. Backend engineers are sitting on customer calls and thinking through the user experience end to end. Members of our product team are shipping full-stack features.
This has changed what we optimize for in hiring. We care less about whether someone has five years of experience in a particular language and more about whether they’re a generalist problem solver that can reason through an unfamiliar problem, learn fast, and ship.
Iterate on the process just like a product.
AI is changing knowledge work fast enough that the way a team operates becomes a compounding advantage or a compounding liability. What are the biggest bottlenecks to shipping? Where are engineers waiting instead of building? What would break if we doubled the number of agents running in parallel? We try to reflect on our process with the same rigor we apply to product decisions, because every improvement multiplies across every subsequent feature the team builds.
Want To Work This Way?
With how we use coding agents today, the natural unit of work has become a customer outcome. Engineers on our team walk into Monday with a plan for a feature or product enhancement, and by Friday they’ve built it. This reorientation from tasks to outcomes is what makes this model work.
It’s also not perfect. Some weeks the process feels seamless; other weeks we find gaps in our specs or realize an agent ran confidently in the wrong direction because we didn’t give it enough context. The model only works with continuous adjustment and iteration, just like you would improve a product itself.
If you want to run ten agents in parallel, own features from schema design to customer demo, and ship something real every week with an unlimited token budget, we’re hiring.

 | A guest post by
|